|
>>
|
No. 148
File
133342328499.png
- (58.95KB
, 600x580
, CUDA_processing_flow_(En).png
)
>>147
(Not OP)
It's useful for supercomputing, to allow small labs to do some heavy computing without buying (time on) a supercomputer, and for password cracking (in other words, it's useful for mostly anything that is parallelizable). You can see a huge list of uses here https://en.wikipedia.org/wiki/GPGPU#Applications . China used 7168 GPUs in one of their supercomputers in 2010, I'm sure you can find something better by now though https://en.wikipedia.org/wiki/Tianhe-I .
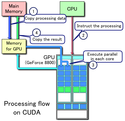
You need to compile the code with a special compiler (the binary runs on the CPU, which communicates to the GPU what to do). Unfortunately, there are three standards you can use: Nvidia's, ATI's and OpenCL (which works both on Nvidia and ATI cards). I don't know about the others, but on Nvidia's CUDA basically you can divide the data to be processed into a matrix and let the GPU take care of it. Doing this in practice, however, can be a bit of a pain since the (global) memory all cores have access to is extremely slow, so you have to use the very limited shared memory between the groups of cores, and different cards have different sizes of memory, different number of cores, etc. For complex problems this can be very difficult. Last time I used CUDA it didn't support recursion.
|